To assess and decide on applicable governance to Generative AI, organisations must first understand what AI model is available to them. They also need to determine how it will be used.
Most organisations are looking to leverage LLMs(Large language models) to implement AI.
Some organisations may also wish to develop their own bespoke models which will drive AI use.
Developing bespoke models could be time consuming and costly. The use of foundational LLMs trained by dedicated LLM developer organisations such as Meta, OpenAI, Anthropic, Amazon, Microsoft and Google is a more efficient and viable option.
Using this approach, there are two levels of governance which need to be applied to the AI model.
- Governance applied to the foundational LLM
- Governance applied to the knowledge source used to fine tune or ground the chosen model (SLM – Small Language Model)
Governance applied to foundational LLM;
When selecting the foundational models to use from the LLM vendors,
- care must be taken to ensure the foundational model has been designed with principles that align with the organisation’s principles.
- Organisations should have AI policies in place which define what is acceptable in terms model quality.
If the foundational model is built in-house,
- governance must be applied to the machine learning process and the algorithms used to develop the model.
- care must be taken to ensure the data used to run the machine learning algorithm is fair and unbiased.
- reasons for excluding or including data must be properly documented and
- the machine learning algorithm such as supervised (eg classification, regression) or unsupervised(eg clustering) must be justified.
Organisations may wish to block certain algorithms to comply with organisational policies. These policies may restrict the type of machine learning algorithms that can be used in the organization due to ethos.
Most foundational LLM developers incorporate Responsible use guidelines in their development. However, each model must be reviewed in terms of its safety, quality, cost, speed, and accuracy. These are known as AI quality dimensions.
When a model scores low on an important metric, organisations may wish to exclude this model from use.
In general, there are three dimensions for evaluating and monitoring generative AI. These include:
- Performance and quality evaluators: assess the accuracy, groundedness, and relevance of generated content.
- Risk and safety evaluators: assess potential risks associated with AI-generated content to safeguard against content risks. This includes evaluating an AI system’s predisposition towards generating harmful or inappropriate content.
- Custom evaluators: industry-specific metrics to meet specific needs and goals.
Source: Microsoft
Some AI development platforms provide tools which can be used to compare models and select the most appropriate model suitable for use. An example of such comparison tool is shown below using Microsoft’s Azure AI Foundry:
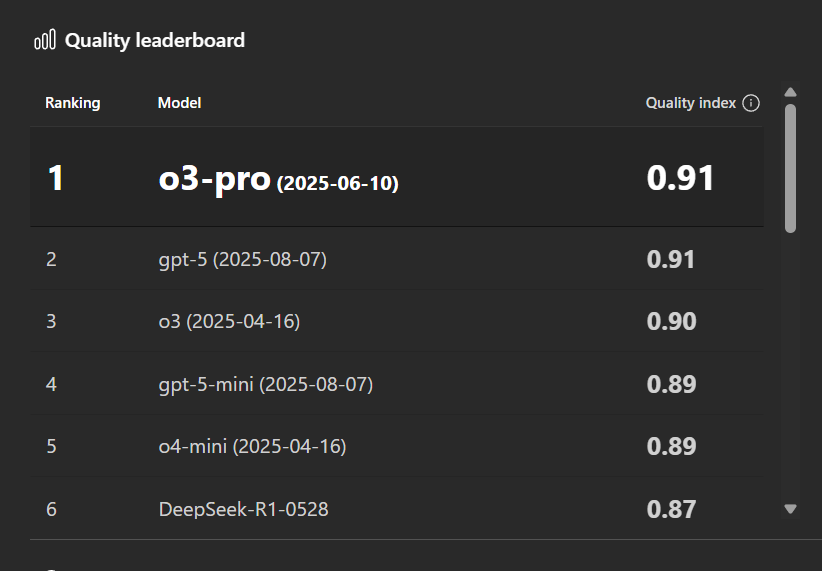
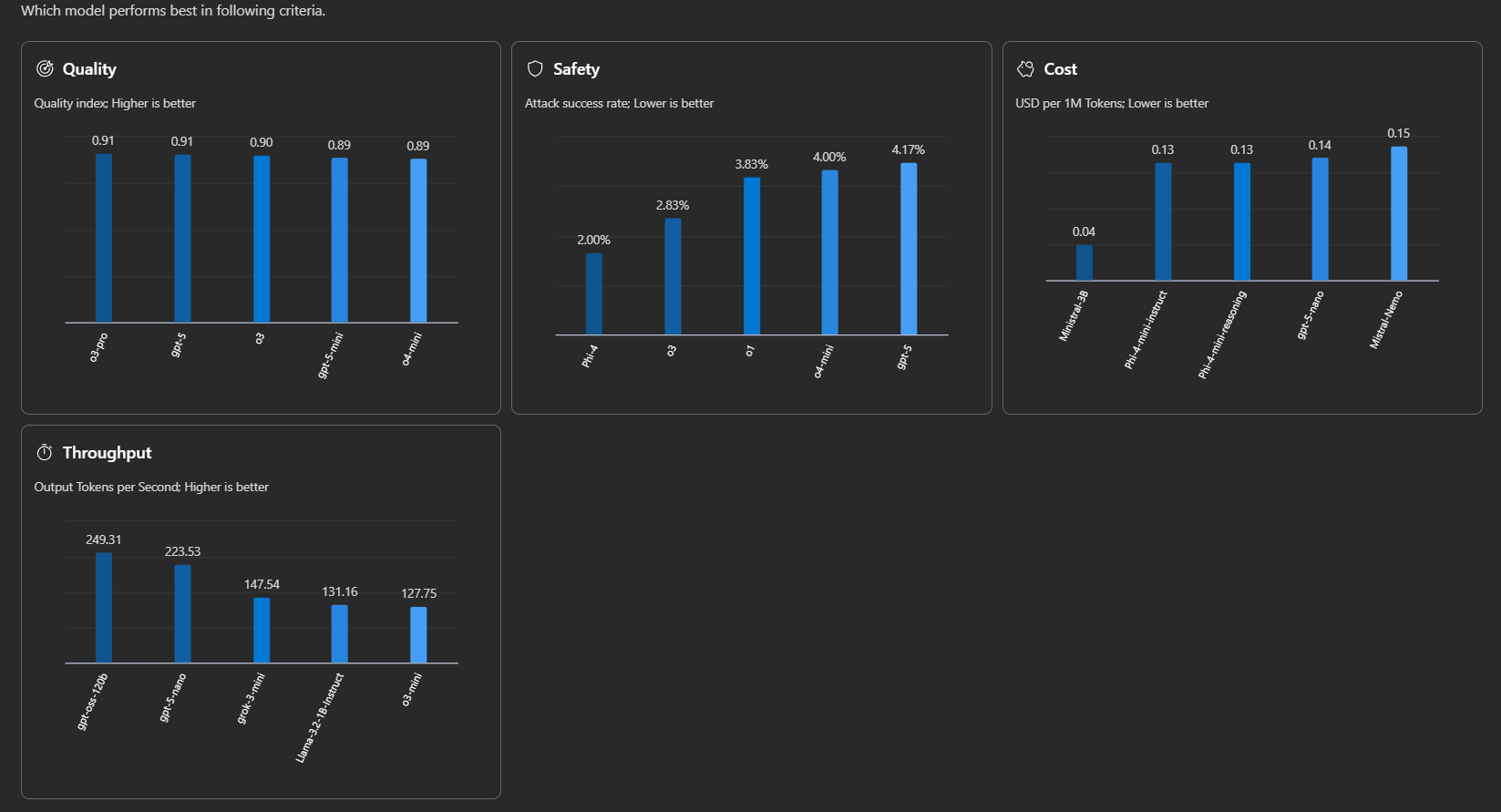
Governance applied to Small Language Model (SLM);
Using LLMs developed by large LLM developers require adaptation to each organisation adopting the model. SLMs are used to train and adapt LLMs to respective organisations. Depending on the use case,
- specify the dataset which will be used to ground the LLM
- context needs to be provided to the model
- a knowledge source should be provided to the Generative AI
- fine tuning of the model should be performed to esnsure further alignment
- organisation tone should be applied which matches the identity and USP of the organisation
- how current the data needs to be must be defined including frequency of refresh and update.
“Grounding refers to the process of ensuring that a system’s outputs are aligned with factual, contextual, or reliable data sources”.
Grounding your language model involves giving the required data and context to the GenAI model so that the correct output is generated. This involves RAG (Retrieval Augmented Generation) where the Generative model is connected to the organisation’s proprietary database.
The output of the agents must be tested for groundedness, relevance, fluency, coherence, and safety. This testing is essential before making the agent available for use across the organisation. An acceptable percentage of accuracy must also be defined which ensures consistent quality.
In using both LLMs and SLMs, policies should be in place to ensure users are qualified to use the agents. Users must be properly trained to use the Generative AI agent for their tasks and users should also be trained to provide the correct prompts to the agent in order to generate the correct information.
Finally, AI Governance should be engaged in AIOps and MLOps so that the data used for training and grounding agents are representative of the organisation .

Leave a comment